The Data Science/AI Product Owner’s Tool Kit
I once saw a t-shirt that read “A Product Owner is a jack of all trades and a master of none”.
I should have bought that shirt.
This article aims at helping POs or even PMs who are currently in charge of AI-driven products or are just in the process of starting out.
Product Owner + <some> data =! AI Product Owner
So let’s break down this title into 2 parts;
- AI
- Product Owner
Let’s start with (2) Product Owner first. How many companies do you know that are struggling with or are in the process (year 1 of…) of their agile transformation? Companies that are transitioning from a classical top-down waterfall method to creating lean self sustaining teams that have the tools and resources to achieve what’s on the roadmap? So what exactly does a Product Owner do?
Scrum.org defines the role of the PO as “responsible for maximizing the value of the product resulting from the work of the Development Team”
This is usually achieved by owning and ordering the product backlog, optimizing the work and value done by the development team and ensuring transparency with multiple stakeholders. Personally I am a big fun the Spotify model; “Agile à la Spotify” ,where the notion of autonomous teams is part of it’s core structure.
At some point or another you will be exposed to some or all of the following duties and “rights of passage”:
Opportunity Analysis
- Defining the Product Vision (Discovery path)
- Understanding the User(s) (Roles, Personnas, Pain Points)
- Competitor Analysis (Who’s doing what and how are they doing it?)
Product Planning
- Journey Mapping
- Creating User Stories and Jobs to be done (JTBD)
- Product Roadmap and alignment (an evolving and continuous cycle)
Development
- Sprint Planning
- Backlog Prioritization and refinement
- Sprint Review and Retrospective
Fun stuff, right? These are well established and have been proven that, when executed correctly, can yield some pretty powerful results.
Now let’s explore the next part; (2) AI. What does the “AI” in AI Product Owner mean and what are the requirements and expectations?
Similar to the agile manifesto, there is the concept of agile data science. I highly recommend spending some time reading Russel Jurney’s Agile Data Science 2.0 with your favorite cup of coffee (or tea). I was hooked from the first few lines
Agile Data Science is an approach to data science centered around web application development. It asserts that the most effective output of the data science process suitable for effecting change in an organization is the web application. It asserts that application development is a fundamental skill of a data scientist. Therefore, doing data science becomes about building applications that describe the applied research process: rapid prototyping, exploratory data analysis, interactive visualization, and applied machine learning.
Unlike traditional agile software development where a defined and concrete output is generated or produced, agile data science is (as it ought to be) an iterative approach that doesn’t necessarily exist to produce GA-ready products. Much of its efforts will be focused on aligning the data science team’s value with the rest of the company.
The Agile Data Science Manifesto is focused on
- Iterate, iterate, iterate: tables, charts, reports, predictions.
- Ship intermediate output. Even failed experiments have output.
- Prototype experiments over implementing tasks.
- Integrate the tyrannical opinion of data in product management.
- Climb up and down the data-value pyramid as we work.
- Discover and pursue the critical path to a killer product.
- Get meta. Describe the process, not just the end state.
My toolkit
Each principle is part of the process and cannot be broken. All of these yield significant results and act as milestones as you move forward with the product development process. Depending on the company’s objectives, there is always a data hierarchy of needs to explore:
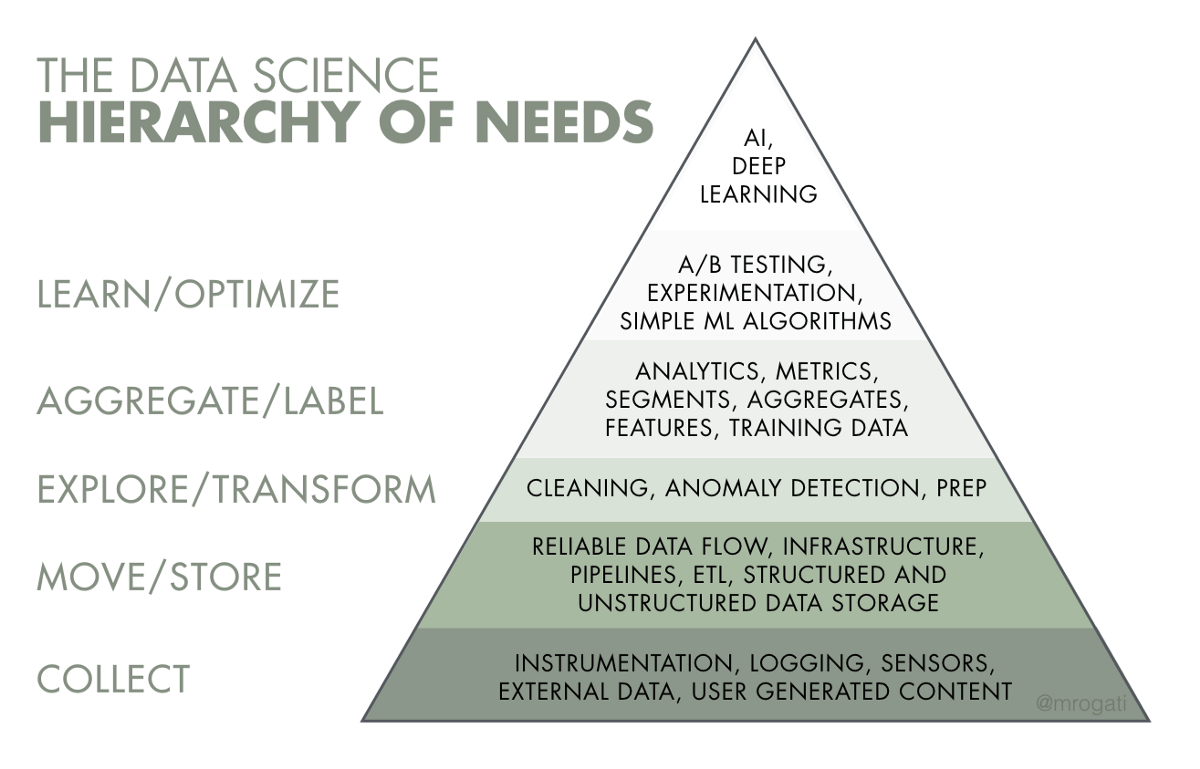 Credits to Monica Rogati’s article on hackernoon
Credits to Monica Rogati’s article on hackernoon
This pyramid can be split into 3 parts;
- What am I collecting? (Collect, Move/Store)
- How do I access and use it? (Explore/Transform, Aggregate/Label)
- What can I do with it? (Learn/Optimize, Produce Value)
Before embarking on a potentially wild goose chase that may last for weeks or months depending on how quickly and easily you can get these questions answered, consider taking a step back and removing your “math” hat. Put yourself in the business owner’s shoes and ask yourself, what am I trying to solve? What business problem or pain point do I want to address? We often make the mistake of doing the reverse first.
“Based on the data mined, I conclude that users who like “X” also like “Y” and we should concentrate our efforts on cross-selling”
As an (AI Product) Owner, it is your responsibility to ensure you are continuously delivering value to the user in the form of:
- A cost saver or revenue generator
- Easy to use/adopt product/feature
How you choose to accomplish that is within the confines of your team’s abilities. The end product may require extensive neural network modeling or it may very well work just as well using a vanilla regression model. What matters to the customer is the value you are delivering for them and not the fact that you used the latest sklearn package to get it done. In fact, that shouldn’t even matter to you. It matters to the engineering team whose goal is to deliver the output in the best possible way and ensure its scalability and robustness.
Agile Data Science is not just about how to ship working software, but how to better align data science with the rest of the organization.
Consider using an “AI Project Canvas” to help you and your stakeholders navigate the expected return of this business idea. This will help you explain the business value of your AI-driven project.
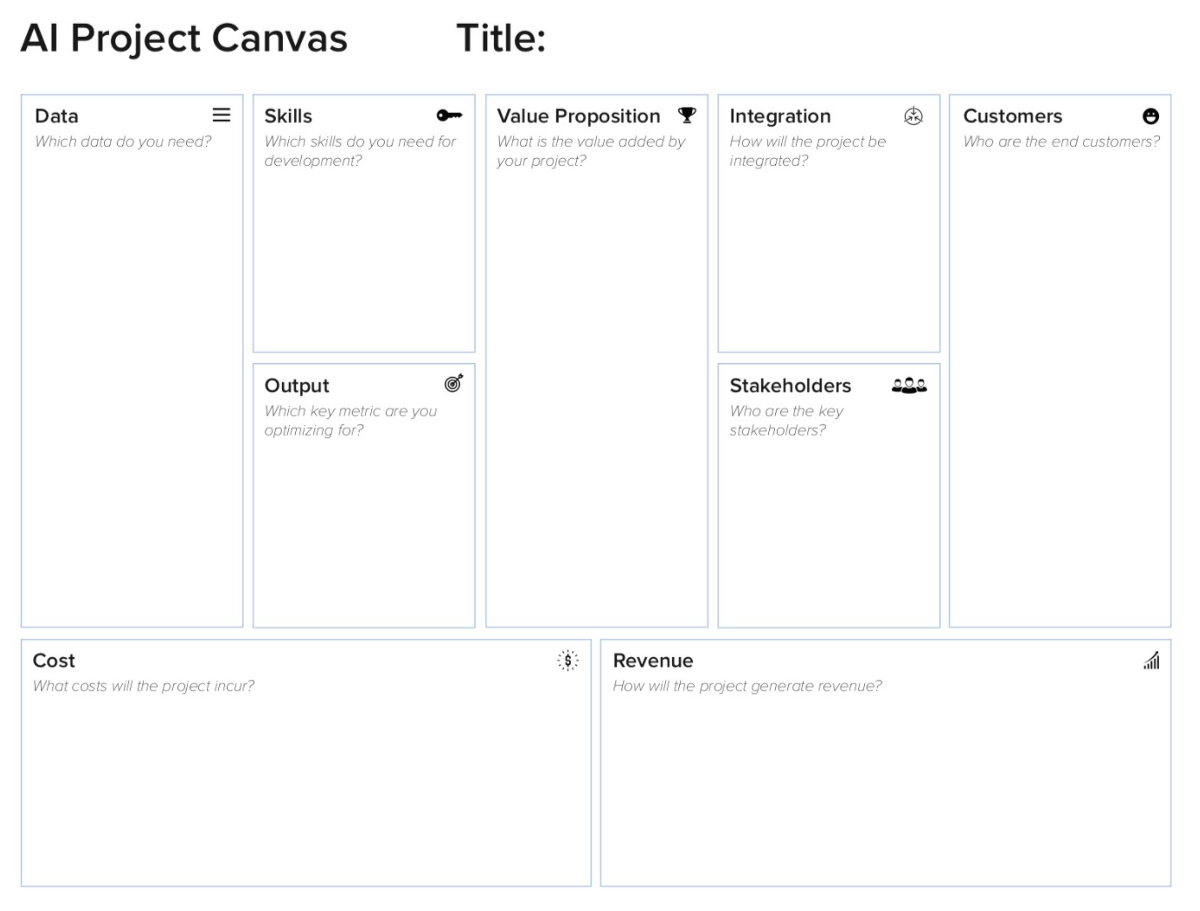
https://drive.google.com/open?id=1u6UT8xHLY1GQqqpa_R5rbqHm2YW8EP2I
Similar to the well known Business Model Canvas, the AI Project Canvas consists of four distinct and unique parts:
- Value Proposition: Where your project lives and dies
- Ingredients: Data, Skills and Output
- Integration: Infrastructure, Stakeholders and Customers
- P&L: Cost and Revenue
You can think of this as the famed “One pager” to formulate, fund, and push your idea forward. Check out Jan Zawadzki’s article for a more in-depth look into the AI project canvas and a neat example to follow.
The perfect mix — Know Your Tech (KYT) meets Know Your Customer (KYC)
I like to think of an AI Product Owner as a hybrid between a traditional PO and a technical PO. To succeed one has to have a good understanding of the customer and the company’s technical boundaries. This can include:
- Systems and techstack used; APIs, data sourcing/storage methods, versioning tools to name a few
- Previous attempts at launching a Data Science-driven project. Bonus points for failed ones.
- Institutional/business knowledge
The first part comes with previous work experience and can often be learned on the job or self-taught through a plethora of online courses. The goal is to seek answers to questions that will help you deliver your AI product. Spend some time with the engineering and release teams to understand how they work and what bottlenecks they are experiencing. Don’t go in there guns blazing trying to solve all their problems. It’s enough to just listen and empathize for the time being. Understanding how the product works from a technical perspective will better prepare you during your pitching and planning phase.
More important than the tech, is how the customer is interacting with the product. Where does the data live? How is it accessed? Are they using microservices, containers, or something else? This part often requires brushing up on your model deployment skills.
The second, and often overlooked part is getting to know the business. This is often the missing ingredient to getting that AI project on the road and convincing your stakeholders of its customer value. Remember, it’s not about the model used, processing time, or hyperparameter tuning; it’s about what value you are delivering to the customer.
Now is the time, ideally in the first 90 days to seek out SMEs within the organization; Client Success, Sales, Professional Services, etc, and understand the role they play in the customer journey and the customer pain points they see first hand. This will also give you the opportunity to explain your role within the organization. It is likely that the role of “AI product owner” is new to many people and setting roles and goals helps for better conversations.
Lastly is determining the Success Metric(s). What will determine the success or failure of this project and how will it be measured? I often find that before deciding which metrics to use in the evaluation scheme it’s often good practice to go evaluate whether you are looking at this from a B2B or B2C perspective or, the often hidden B2B2C perspective. At that point, the right “signals” will emerge and will add clarity to the evaluation piece.
Your (success) metrics should align with your overall product goals which should tie into your overall company strategy. It is usually good practice to avoid vanity metrics like page views/clicks as they don’t always correlate to product success. Teams should align not only on a mix of metrics but also a target to hit (ideally backed by some internal data already available).
E.g. We believe adding a chatbot on the checkout page, will reduce our bounce rate from 20% (current benchmark) to 10% (target)
Success metrics should be discussed, evaluated, and agreed upon in the early stages of the ideation phase. Changing them as the project progress will only induce bias and will skew the original intent.
Key Takeaways
Here’s what you need to really maximize your effort and set the right pace for your AI project
- Understand what your role is and what you are responsible for (PO duties)
- Agile Data Science is not the same as agile software engineering. Delivering production software is fundamentally different then delivering actionable insights or any type of recommendations.
- Seek the pain point and try to solve it. Leverage the AI Project Canvas to help bring your AI-driven product or project to life.
- Understand and map out the data pyramid to help you in your journey on data discovery
- KYT- “Know your Tech”. Get to know the company’s tools and systems and how they integrate with the product.
- KYC- “Know your customer”. Seek out SMEs. Key members from different teams have different perspectives of client needs and wants and often are at the frontline of that conversation. Leverage these connections to understand and build great products.
- Measure your success. Use data-driven KPIs that sync up with your organization’s goals to track how your project lives or dies.
If you’re starting a new job as an AI Product Owner or just looking for some quick tips I hope this helps!
If this post added any value to you, your role or your daily reading then feel free to comment, like, or share. Your constructive criticism is always welcomed and encouraged!